

This post is also available in:
Los leptocurtofóbicos sienten un deseo insaciable de transformar cualquier dato hasta que se asemeje lo máximo posible a una distribución normal. En los tiempos (no tan remotos) en que este tipo de transformaciones no lineales no eran sencillas de realizar, la fobia se mantenía controlada. Pero con el advenimiento de paquetes informáticos capaces de realizar todo tipo de transformaciones con solo apretar un botón, la leptocurtofobia se ha extendido.
Leptocurtosis significaba, originalmente, "montículo delgado" y se refería a los modelos de probabilidad que tienen un montículo central más estrecho que el de una distribución normal. En la práctica, debido a las matemáticas, la leptocurtosis se refiere a todos aquellos modelos de probabilidad cuyas colas son más pesadas que la distribución normal. La mayoría de las distribuciones leptocúrticas están sesgadas..
Si usted pregunta de manera rutinaria si los datos están distribuidos normalmente y los transforma para que parezcan menos leptocúrticos y más «en forma de montículo», perdóneme que le siga, pero usted sufre de leptocurtofobia.

Los orígenes de la leptocurtofobia se remontan a la década de los ochenta, cuando comenzó a extenderse la enseñanza del control estadístico de procesos (SPC). En los años previos, en EEUU solo dos universidades enseñaban SPC y solo unos pocos formadores disponían de alguna experiencia real con SPC. Esto dio como resultado que muchos formadores de SPC de la década de los 80 fueran, forzosamente, neófitos. Como consecuencia de ello, se extendieron un gran número de enseñanzas que solo pueden clasificarse como supersticiones. Una de ellas es que los datos han de estar distribuidos normalmente antes de poder confeccionar un gráfico de control.
Cuando W. Shewart creó el gráfico de comportamiento del proceso, buscaba una manera de separar la variación rutinaria (causas comunes) de la variación excepcional (causas asignables). Como la variación excepcional domina, por definición, a la variación rutinaria, Shewhart dedujo que la forma más fácil de diferenciarlas era filtrar cuanta más variación rutinaria mejor. Muy pronto descubrió que los límites tres sigma cubren toda o casi toda la variación rutinaria para prácticamente todos los tipos de datos.
Veamos la siguiente gráfica, que ya apareció en otra entrada de esta bitácora.

Hemos representado seis modelos de probabilidad diferentes para la variación rutinaria. Estos modelos van de la distribución uniforme a la distribución exponencial (los últimos tres modelos son leptocúrticos). Cada uno de ellos se encuentra estandarizado para que todos dispongan de media cero y desviación estándar de 1,00. La figura muestra también los límites de tres sigma y la proporción del área debajo de cada curva que cae dentro de esos límites de tres sigmas.
Algunas enseñanzas que se aprenden de la anterior figura son:
- Los límites de tres sigma filtrarán prácticamente todas las variaciones rutinarias con independencia de la forma del histograma. Los seis modelos son radicalmente distintos entre sí, pero aun con todo, los límites de tres sigmas cubren el 98 por ciento al 100 por ciento del área bajo la curva.
- Cualquier conjunto de datos que se encuentre fuera de los límites de tres sigma, será una señal potencial de cambio en el proceso. Dado que será extraño que la variación de rutina lleve a un evento fuera de los límites de tres sigma, lo más probable será que cualquier punto que caiga fuera de dichos límites sea una señal de un cambio de proceso.
- Los límites simétricos de tres sigma funcionan con datos sesgados. Cuatro de los seis modelos están sesgados. A medida que exploramos las figuras, vemos que no importa cuán sesgado sea el modelo ni qué tan pesada son las cosas: los límites de tres sigma se estiran esencialmente tanto como las colas. Esto significa que la longitud de la cola determinará la distancia de tres sigmas en cada caso y que los límites de tres sigmas cubrirán la mayor parte de la cola alargada, sin importar cuán sesgados estén los datos. «Pero eso ciertamente hace que el otro límite parezca tonto«, responderá usted. Y sí, es verdad, lo hace. En la mayoría de los casos, los datos sesgados se producen cuando los datos se acumulan en una barrera o condición de contorno. Cuando un valor de límite cae dentro de los límites calculados, el límite tiene prioridad sobre el límite calculado y el gráfico es de un solo lado. Cuando esto sucede, el límite restante cubre la cola larga y nos permite separar la variación rutinaria de las posibles señales de desviación del límite. es así como los límites simétricos de tres sigma pueden funcionar bien con datos sesgados.
- Cualquier incertidumbre sobre dónde dibujar las líneas de tres sigma no afectará en gran medida la cobertura de los límites. Las curvas son tan planas en el momento en que alcanzan la vecindad de los límites de tres sigmas que cualquier error que podamos cometer al estimar los límites tendrá, como máximo, un efecto mínimo sobre el funcionamiento del gráfico.
Estos seis modelos de probabilidad resumen lo que uno puede encontrarse al examinar miles de modelos de probabilidad diferentes para distintas familias de modelos de uso común. Los límites tres sigma funcionan por fuerza bruta. Son lo suficientemente generales que pueden trabajar con todos los tipos y formas de histogramas. Trabajan con datos sesgados y funcionan incluso cuando los límites se basan en pocos datos.
Usemos a continuación el modelo de probabilidad exponencial de la figura anterior para ilustrar este comentario. Con dicho modelo hemos generado los valores mostrados en las filas de la siguiente tabla, cuyo histograma se muestra a continuación. Dado que dichos valores deberían, por definición, mostrar solo variación rutinaria, esperaremos encontrar casi todas las observaciones dentro de los límites tres sigma. Por tanto, el gráfico de comportamiento del proceso funcionará como se anuncia incluso con datos sesgados.

Cien observaciones de la distribución exponencial estandarizada
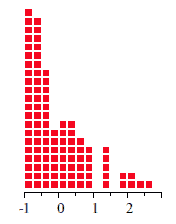
Histograma de las cien observaciones exponenciales

Gráfica X para las cien observaciones exponenciales
No se necesita verificar la normalidad de los datos, ni tampoco definir una distribución de referencia antes de calcular los límites. En realidad, no hay necesidad alguna de complicarse la vida lamentablemente.
Transformaciones de los datos
«Pero, oiga, ¡el software sugiere transformar los datos!»
¿Y qué quiere que le diga? Ningún dato contiene un significado aparte del de su contexto. El análisis comienza con el contexto, es impulsado por el contexto y termina con los resultados interpretados en el contexto de los datos originales. Este principio requiere que siempre haya un vínculo entre lo que se hace con los datos y el contexto original de los mismos. Cualquier transformación de los datos corre el riesgo de romper este enlace.
Si una transformación tiene sentido tanto en términos de los datos originales como de los objetivos del análisis, entonces la transformación será correcta. Este tipo de transformaciones correctas podrían ser, por ejemplo, calcular los promedios diarios o semanales en lugar de los valores por hora, o el uso de proporciones en lugar de conteos. Solo el usuario puede determinar cuándo una transformación tiene sentido en el contexto de los datos (el software no conoce el contexto).
Una segunda clase de transformaciones serían aquellas que vuelven a escalar los datos para lograr ciertas propiedades estadísticas. Y es realmente el único tipo de transformación que debería sugerir cualquier software. El objetivo es hacer que los datos parezcan más «distribuidos normalmente» para tener una «estimación de la dispersión que sea independiente de la estimación de la ubicación». Por desgracia, estas transformaciones tienden a ser muy complejas y son no lineales por naturaleza, involucrando funciones exponenciales, exponenciales inversas o logarítmicas. (¿Usted sabe qué demonios representa el logaritmo del porcentaje de envíos a tiempo?). este tipo de transformaciones no lineales distorsionarán los datos de dos maneras: en un extremo del histograma, los valores que estaban originalmente muy separados ahora estarán muy juntos; en el otro extremo del histograma, los valores que originalmente estaban cerca juntos ahora estarán muy separados.
Para ilustrar el efecto de las transformaciones para lograr propiedades estadísticas, utilizaremos los siguientes tiempos de tránsito de acero fundido en una colada.

Tiempos de tránsito de metal fundido (en minutos)
Construyamos con ellos el histograma correspondiente.

Histograma de tiempos de tránsito de metal fundido
Dada la naturaleza sesgada de los datos en el histograma, algunos programas sugerirán el uso de una transformación logarítmica. Hagámoslo. Tomemos el logaritmo natural de cada uno de estos tiempos y representemos el histograma modificado.

Histograma de los logaritmos de tiempos de tránsito
En esta última gráfica, las escalas horizontales muestran los valores originales y los valores transformados. Es interesante observar que, en el histograma sin transformar, los valores a la izquierda están espaciados mientras que los de la derecha se amontonan juntos, y que después de la transformación, la distancia de 20 a 25 minutos es aproximadamente del mismo tamaño que la distancia de 140 a 180 minutos. ¿Cómo explicar esto al jefe?
Por sí misma, la distorsión de los datos es suficiente para poner en tela de juicio la práctica de transformar los datos para lograr propiedades estadísticas. Sin embargo, el impacto de estas transformaciones no lineales no se limita a los histogramas. Veamos el gráfico X para los datos originales no transformados.

11 de 141 tiempos de tránsito están por encima del límite superior, lo que confirma la impresión dada por el histograma de que estos datos provienen de una mezcla de dos o más procesos. Sin embargo, si transformamos los datos antes de colocarlos en una tabla de comportamiento del proceso, observamos lo siguiente:

¡Ya no hay puntos fuera de los límites! Claramente la transformación logarítmica ha borrado las señales. ¿De qué sirve una transformación que cambia el mensaje contenido en los datos? La transformación de los datos para lograr propiedades estadísticas es simplemente una forma compleja de distorsionar tanto los datos como la verdad.
Los resultados que se muestran aquí son típicos de lo que sucede con las transformaciones no lineales de los datos originales. Estas transformaciones ocultan las señales contenidas dentro de los datos simplemente porque se basan en cálculos que suponen que no hay señales dentro de los datos.
Para una medida descriptiva de la ubicación usualmente usamos el promedio, que se basa simplemente en la suma de los datos. Sin embargo, una vez que dejamos atrás el promedio, las fórmulas se vuelven mucho más complejas. Para una medida descriptiva de dispersión usamos comúnmente la desviación estándar global, que es una función de las desviaciones cuadradas del promedio. Para las medidas descriptivas de la forma, usamos comúnmente las estadísticas de sesgo y curtosis que, respectivamente, dependen de la tercera y cuarta potencias de las desviaciones de los datos del promedio. Cuando agregamos los datos de esta manera y usamos la segunda, tercera y cuarta potencias de la distancia entre cada observación y el valor promedio, asumimos implícitamente que estos siete cálculos tienen sentido. Tanto si se trata de medidas de dispersión, como de medidas de sesgo, o incluso medidas de curtosis, cualquier estadística descriptiva de alto orden que se calcule globalmente se basa implícitamente en una suposición muy fuerte de que los datos son homogéneos.
Cuando los datos no son homogéneos, no es la forma del histograma lo que está mal, sino que el cálculo y el uso de las estadísticas descriptivas son erróneos. No necesitamos distorsionar el histograma para hacer que los valores transformados sean más homogéneos, pero sí debemos detenernos y cuestionar qué significa la falta de homogeneidad en el contexto de las observaciones originales.
Entonces, ¿cómo determinar cuándo un conjunto de datos es homogéneo? ¡Justo ese es el propósito del gráfico de comportamiento del proceso! Transformar los datos para lograr propiedades estadísticas antes de colocarlos en una tabla de comportamiento del proceso es un ejemplo de cómo hacerlo todo al revés.
El enfoque de Shewhart, con sus límites genéricos de tres sigma calculados empíricamente a partir de los datos, ni siquiera requiere la especificación de un modelo de probabilidad: «… no nos preocupa la forma funcional del universo (es decir, el modelo de probabilidad), sino simplemente la suposición de que existe un universo«. La cursiva es del original (Statistical Method from the Viewpoint of Quality Control, pág. 54)
Transformar los datos para lograr propiedades estadísticas es engañarse uno a sí mismo y a quienes no saben suficiente estadística para advertir el engaño. Verificar la normalidad de los datos antes de colocarlos en un gráfico de control es practicar vudú estadístico. Transformar los datos antes de usarlos es un error de colosales proporciones.