

This post is also available in:
Si recopilamos datos de un proceso es para pasar a la acción: tomar medidas. Cuando estas medidas se refieren a la situación actual o presente de un proceso, entonces el análisis de los datos se limita a medir bien. Esto es lo que W. Deming denominó un «estudio enumerativo«.
En un estudio enumerativo del 100% de los elementos no hay inferencia estadística alguna. La única incertidumbre es la posibilidad de que hayamos cometido algún error en la medición. Si esta incertidumbre es insignificante, decimos que las mediciones son exactas. Cuando la incertidumbre es sustancial, tendremos que evaluar el procedimiento de medición.
Descripciones basadas en muestras
Una inspección al 100% puede ser muy costosa y no funciona cuando las mediciones son destructivas. Por eso lo habitual es trabajar con una muestra del total. Cuando solo se mide parte del material en cuestión, la descripción de la situación actual de un proceso depende de cuán buena es la suposición de que los elementos medidos en la muestra son esencialmente los mismos que los elementos que no medidos. Y es esta suposición, justamente, la clave de tomamos después la acción correcta.
La lógica dicta que, para tener una muestra representativa, necesitamos usar un método de muestreo que asegure que cada elemento tiene la misma posibilidad de ser incluido en la muestra. Por esto mismo el muestreo aleatorio es el enfoque preferido para los estudios enumerativos. Cuando disponemos de una muestra aleatoria, la incertidumbre se calcula por inferencia estadística. Las estadísticas descriptivas se toman como estimaciones puntuales del lote en su conjunto. Los intervalos de confianza se utilizan para definir rangos de valores descriptivos consistentes con los datos observados. Y se pueden usar pruebas para determinar si el lote cumple con algún valor de especificación.
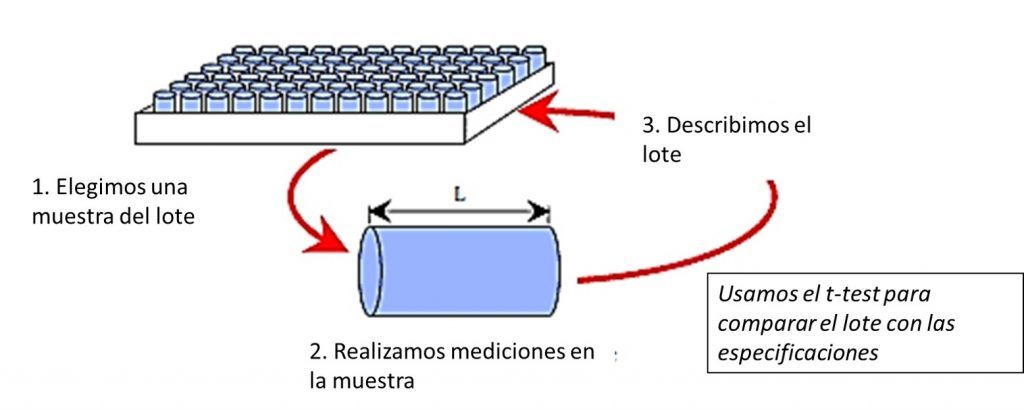
Por tanto, en un estudio enumerativo, si la muestra se ha obtenido de una manera que pueda hacerla representativa del lote, se puede usar inferencia estadística para cuantificar la incertidumbre al extrapolar la muestra al lote. Y la acción final tomada (sobre el lote) dependerá de dos cosas: la representatividad de la muestra y el resultado de la inferencia estadística.
Por supuesto, si la muestra no representa correctamente el lote, tanto las inferencias como las acciones tomadas pueden ser incorrectas. Son las consecuencias de una acción incorrecta las que determinan el esfuerzo que se debe aplicar para obtener una muestra razonablemente representativa. Los planes de muestreo aleatorio son los preferiso, pero en la práctica pueden ser complejos. Lo que es razonable para el papel puede no ser tan factible para la producción. La solución pasa por usar muestras sistemáticas en lugar de un muestreo aleatorio.
Lo que es cierto es una cosa: con independencia de cómo se obtenga la muestra, antes de tomar decisiones hay que valorar bien la representatividad para la muestra.
El t-test de dos muestras
El problema enumerativo lo resolvió Gossett (un estadístico que trabajaba para Guinness, en Dublín, seleccionando las mejores variedades de cebada) con la denominada «prueba t de Student» para dos muestras, posteriormente generalizada por el grandísimo Ronald Fisher (autor de la «prueba F«).

Fisher analizaba resultados de experimentos agrícolas. Quería predecir el comportamiento de dos variedades de trigo en el futuro. No solo pretendía saber si la variedad A tenía un rendimiento más alto que la variedad B, sino si la diferencia persistiría en las siguientes temporadas de crecimiento. Ya no era suficiente una descripción de lo que estaba sucediendo: había que extrapolar los datos del presente (y del pasado) al futuro.
En general, en agricultura este tipo de predicción se ha resuelto empleando un gran número de parcelas experimentales que representan, cada una, diferentes condiciones ambientales. Las parcelas se asignan de una manera estructurada, pero aleatoria, a cada una de las variedades que se someten a prueba. Si se puede encontrar una diferencia detectable entre las dos variedades para alguna de todas estas condiciones, entonces es razonable esperar que esta diferencia persista de una temporada a otra. En este contexto, el análisis estadístico consiste en filtrar el ruido para encontrar señales que correspondan a los tratamientos que se están estudiando. Dicho de otro modo, el nivel alfa establece cómo se han separado las señales del ruido. Cuando se encuentra una señal potencial (es decir, cuando se observa un valor de p más pequeño que el nivel alfa), quienes disponen del conocimiento apropiado han de valorar la utilidad del resultado y bajo qué condiciones dicho resultado puede ser predictivo.
Pero, ¿qué sucede cuando no podemos muchas unidades experimentales diferentes? En la industria no es común el lujo de contar con múltiples unidades experimentales y tampoco se puede esperar un año entero para recopilar datos útiles. Los datos se deben recopilar, analizar y medir en un calendario estricto y con un presupuesto exiguo.
Predicciones a futuro
Cuando se da paso a la acción, no nos preocupan las condiciones presentes sino las futuras. Debemos extrapolar de los elementos medidos a los elementos que aún no se han producido. En consecuencia, todo el interés se centra en el proceso. Este uso de los datos para hacer predicciones de forma que podamos actuar en el proceso es lo que Deming denominó un «estudio analítico«. Todos somos conscientes de lo importante que es para los negocios predecir el futuro…
Como no podemos medir lo que aún no se ha producido, las observaciones empleadas en un estudio analítico a menudo son las mismas que las empleadas en un estudio enumerativo. Sin embargo, predecir es diferente a describir: el análisis también será, por tanto, diferente.
La primera diferencia se encuentra en la interpretación de los datos. No importa si representan el 100% del producto fabricado o tan solo una fracción. Y dado que es imposible tomar una muestra aleatoria del futuro, las observaciones se convierten de inmediato en muestras de análisis con independencia de cómo se obtuvieran. La difusión temporal de los datos se convierte en la principal consideración. Esto otorga gran importancia a los métodos sistemáticos de selección de elementos (a diferencia de los métodos de muestreo aleatorio utilizados en estudios enumerativos). Por supuesto, los datos tienen que ser organizados racionalmente. es decir, debemos respetar la estructura y el contexto de los mismos al realizar la predicción. Esta es la razón por la cual los estudios analíticos ponen énfasis en el muestreo racional y en la sub-agrupación racional en oposición a los muchos procedimientos de muestreo aleatorio desarrollados para los estudios enumerativos.

Una segunda diferencia entre los estudios enumerativos y los estudios analíticos es el tipo de estadística utilizada. Los primeros tienden a basarse en medidas simétricas de dispersión (medidas globales), mientras que los estudios analíticos utilizan medidas de dispersión que dependen de la secuencia de datos en el orden del tiempo o la estructura del experimento (medidas dentro del subgrupo). Dado que la predicción implica una caracterización del comportamiento del proceso a lo largo plazo, esta distinción es crucial.
Análisis de datos para estudios analíticos
El propósito de un estudio analítico es tomar acción en el proceso. Las acciones involucran las entradas del proceso, por lo que resulta útil distinguir dichas entradas en dos grupos: los «factores de control«, usados para controlar el proceso, y los «factores no controlados«, que son todas las demás, sean o no conocidas.
Si mantenemos constantes los factores de control, evitamos la variación del flujo de productos. Por tanto, los factores de control proporcionan una manera de ajustar el promedio del proceso, pero tienen poco o ningún impacto en la variación del mismo.
Prácticamente todas las variaciones del proceso provendrán del grupo de factores no controlados. Para reducir la variación en el flujo de productos y, por tanto, para reducir los costes excesivos de producción, tendremos que mover algunas entradas del conjunto de factores no controlados al conjunto de factores de control. Esto significa que si queremos ajustar el promedio del proceso, deberemos estudiar los niveles para el grupo de factores de control, pero si queremos reducir la variación del proceso, tendremos que estudiar las entradas en el grupo de factores no controlados.

Aquí es la economía se vuelve tirana No podemos permitirnos que cada posible entrada sea un factor de control, incluso si tuviéramos suficiente conocimiento para hacerlo. Además, el gran número de entradas en el grupo de factores no controlados hace que sea extremadamente difícil identificar qué entradas debemos estudiar. En lugar de estudiar los efectos de los insumos seleccionados, necesitamos un enfoque que no solo nos permita conocer la gran cantidad de insumos existentes en el grupo de factores no controlados, sino que nos permita hacerlo sin tener que identificar entradas específicas de antemano. ¿Suena prolijo? No se preocupe: es justo lo que nos permite hacer el gráfico de comportamiento del proceso.
Un gráfico de comportamiento (o control) del proceso no hace suposiciones sobre el mismo o los datos que lo caracterizan. Simplemente permite que los datos definan tanto el potencial del proceso genérico como su rendimiento real. Luego combina ambos en un solo gráfico para permitir al usuario caracterizar el proceso como predecible o impredecible.

Dado que el grupo de factores no controlados es la fuente de variación en el flujo, esta caracterización del comportamiento del proceso nos dice algo sobre dicho grupo de factores no controlados.
Proceso predecible
Si el proceso se ha comportado de manera predecible en el pasado, supondremos que el grupo de factores no controlados consiste en un gran número de relaciones de causa-efecto donde ninguna causa tiene un efecto dominante. Se dice que la variación rutinaria de un proceso predecible es el resultado de causas comunes.
Aquí sería un error seleccionar una entrada no controlada y agregarla al conjunto de factores de control. La gran cantidad de entradas, más la ausencia de una entrada única con carácter dominante, es lo que ocasiona que hacer cambios en el proceso no sea económico. Cuando se opera de manera predecible, un proceso se lleva hasta su máximo potencial. Tendrá varianza mínima, consistente con la operación económica. Por eso tratar de controlar una causa común es una pésima estrategia (bajísima rentabilidad).
Cuando el proceso ha sido predecible en el pasado, es lógico esperar que continúe predecible en el futuro. El comportamiento del pasado es la base de nuestras predicciones de futuro.
Proceso impredecible
Si el proceso muestra evidencia de ser impredecible, hemos de pensar que el grupo de factores no controlados contiene una o más relaciones causa-efecto dominantes que aparecen por encima de la variación rutinaria. Las causas con estos efectos dominantes se denominan causas asignables de variación excepcional.
En este caso, el proceso ofrece pruebas sólidas de que hay entradas no controladas con efectos dominantes. Cuando un proceso opera de manera impredecible, está operando por debajo de su potencial completo. No tendrá una variación mínima y no será económico. Cuando hay causas asignables casi siempre resulta económico identificar dichas entradas de proceso y hacerlas parte del conjunto de factores de control.
Esta es una estrategia de alta rentabilidad por dos razones. Cuando hacemos que una causa asignable forme parte del grupo de factores de control, no solo obtenemos un elemento adicional para ajustar el promedio del proceso, también eliminamos una gran parte de la variación del producto. De esta manera, aunque el proceso haya sido impredecible en el pasado, aprendemos cómo mejorarlo y nos acercamos a operarlo de manera predecible en el futuro.
No es lógico suponer que un proceso que ha sido operado de manera impredecible en el pasado vaya a volverse espontáneamente predecible en el futuro. A menos que intervengamos, las causas asignables, con sus efectos dominantes, continuarán llevando nuestro proceso de manera errática. Por tanto, aunque nuestros límites de proceso natural puedan aproximarse al potencial de proceso hipotético, ningún cálculo puede proporcionar una predicción confiable de lo que realmente producirá un proceso impredecible.

En resumen
Los estudios enumerativos buscan describir el presente. Enumeran o estiman lo existente para adoptar medidas al respecto. Las inferencias estadísticas pueden cubrir la incertidumbre involucrada en la extrapolación de una muestra representativa al lote, pero no pueden cuando la muestra no es representativa. Se debe utilizar algún criterio para decidir si la muestra es representativa antes de justificar la acción.
Imponer las técnicas y requisitos de los estudios enumerativos a los estudios analíticos es signo de confusión. Los estudios analíticos buscan hacer predicciones para que se puedan tomar acciones apropiadas en el proceso de producción. Aquí la extrapolación es a lo largo plazo en el tiempo y todas las muestras se convierten en muestras de juicio o análisis. La distribución temporal de los datos y la selección sistemática de los elementos a medir son importantes.
En un estudio analítico, experimentar con los niveles de los factores de control puede permitir modificar el promedio del proceso, pero rara vez conducirá a una reducción en la variación del proceso. La variación del proceso proviene del grupo de factores no controlados y el gráfico de control del proceso permite considerar todos los factores no controlados de una sola vez.
Un proceso predecible existirá como una entidad bien definida. Tendrá un promedio de proceso constante y funcionará con una variación mínima. Podemos usar nuestros datos para hacer predicciones y no será preciso realizar ninguna acción.
Un proceso impredecible no funciona con variación mínima. Las estimaciones de las características del proceso serán prematuras. Se requiere acción. Hasta que no se encuentren las causas asignables y formen parte del conjunto de factores de control, toda predicción es inútil. Trabajar para hacer que las causas asignables formen parte del conjunto de factores de control es una estrategia de alta rentabilidad.
Buscar causas asignables de variación excepcional cuando el proceso se realiza de manera predecible es una pérdida de tiempo y esfuerzo. Tratar de controlar las causas comunes de la variación de rutina es una estrategia de baja rentabilidad.
Asumir que el pasado predecirá el futuro cuando las causas asignables estén presentes es simplemente una ilusión. Si no se controlan las causas asignables de variación excepcional, aumentará la variación del proceso y dará como resultado costos adicionales.
Finalmente, la única razón para recopilar datos es la de poder tomar medidas. Las probabilidades asociadas con el análisis de datos no pueden justificar ninguna acción. Ya sea un análisis enumerativo o analítico, los resultados deberán evaluarse a la luz del conocimiento de la materia antes de poder tomar medidas. Aunque las estadísticas matemáticas y las probabilidades resultantes hagan parecer que el problema de decisión es riguroso y exacto, al final las acciones siempre han de involucrar algún elemento de juicio.